
دیتا (داده) همه جا است و هر روز نیز بیشتر میشود. به همین دلیل، مهندسی نرمافزار شاخهای به نام مهندسی داده را به خودش اضافه کرده است. مهندسان داده روی جابهجایی، تغییر، و ذخیرهسازی این حجم عظیم اطلاعات تمرکز میکنند. شاید آگهیهای استخدام «دادههای حجیم» را دیدهاید و از مدیریت دادههایی در ابعاد پتابایت هیجانزده شدهاید. شاید تا به حال حتی اسم مهندسی داده را هم نشنیده باشید، اما به چگونگی مدیریت حجم عظیم دادهای که امروزه برای اکثر برنامهها ضروری است، علاقهمند باشید.
در این مقاله، به طور کلی با حوزهی مهندسی داده آشنا میشوید، از جمله اینکه مهندسی داده چیست و چه نوع کارهایی را شامل میشود. اگر به علم داده نیز علاقمند هستید، این مجموعهی آموزشی بینظیر را دنبال کنید.
مهندسان داده چه کار میکنند؟
مهندسی داده حوزهای بسیار گسترده است که عناوین مختلفی را شامل میشود. در بسیاری از سازمانها، حتی ممکن است عنوان خاصی برای آن وجود نداشته باشد. به همین دلیل، احتمالاً بهتر است ابتدا اهداف مهندسی داده را شناسایی کنیم و سپس در مورد اینکه چه نوع کاری نتایج مطلوب را به همراه میآورد، بحث کنیم.
هدف نهایی مهندسی داده، ارائه جریانِ دادهی منظم و یکپارچه برای فعال کردن کار مبتنی بر داده است، مانند:
- آموزش مدلهای یادگیری ماشین
- انجام تحلیل اکتشافی دادهها
- پر کردن فیلدها در یک برنامه با دادههای خارجی
این جریان داده میتواند از طریق روشهای مختلفی به دست آید و مجموعه ابزار، تکنیکها و مهارتهای خاص مورد نیاز تا حد زیادی در تیمها، سازمانها و نتایج مورد نظر متفاوت خواهد بود. با این حال، یک الگوی رایج، خط لوله داده (data pipeline) است. این یک سیستم است که از برنامههای مستقل تشکیل شده است که عملیات مختلفی را روی دادههای ورودی یا جمعآوریشده انجام میدهد.
خطوط لوله داده اغلب در چندین سرور توزیع شدهاند و دادهها میتوانند از هر جایی بیایند، مثلا دستگاههای هوشمند، ماشینها یا حتی فعالیت کاربران در یک وبسایت.
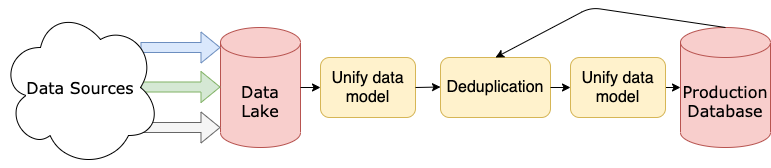
مهندسان داده مسئول ساختن “خط لوله داده” هستند. خط لوله داده شبیه یک مسیر است که اطلاعات از آن عبور میکند و در طول مسیر تمیز و مرتب میشود. در نهایت، این دادههای سازماندهی شده برای چیزهای مختلفی مانند آموزش هوش مصنوعی یا ساخت گزارشهای تجاری مورد استفاده قرار میگیرد.
بعضی از سازمانهای بزرگ حتی “پلتفرمهای داده” میسازند. این پلتفرمها شبیه انبارهای بزرگی هستند که دادههای مختلف را برای تیمهای مختلف سازمان نگهداری میکنند. برای مثال، تیمی که روی هوش مصنوعی کار میکند به اطلاعات متفاوتی نسبت به تیمی که گزارشهای مالی تهیه میکند نیاز دارد.
اگر با توسعه وب آشنایی دارید، ممکن است این ساختار را شبیه به الگوی طراحی Model-View-Controller (MVC) بدانید با MVC، مهندسان داده مسئول مدل هستند، تیمهای هوش مصنوعی یا BI روی نماها کار میکنند و همه گروهها روی کنترلر همکاری میکنند. ساخت پلتفرمهای دادهای که به تمام این نیازها پاسخ دهد، به اولویتی مهم در سازمانهایی با تیمهای متنوعی که به دسترسی به داده متکی هستند، تبدیل میشود.
حالا که کمی با کاری که مهندسان داده انجام میدهند و اینکه چگونه با مشتریانی که به آنها خدمت میکنند در ارتباط هستند آشنا شدید، مفید خواهد بود که کمی بیشتر در مورد آن مشتریان و مسئولیتهایی که مهندسان داده در قبال آنها دارند، بیاموزید.
وظایف مهندسان داده
مهندسان داده نه تنها مسئول رساندن دادهها هستند، بلکه باید آنها را سازماندهی هم بکنند. این سازماندهی شبیه دستهبندی کردن اطلاعات در قفسههای یک کتابخانه است. مهندسان داده با انجام کارهای زیر، استفاده از دادهها را برای دیگران آسان میکنند:
- از بین بردن موارد تکراری
- رفع مغایرت در دادهها
- طبقهبندی دادهها بر اساس یک مدل مشخص
این فرآیندها میتوانند در مراحل مختلف انجام شوند. برای مثال، فرض کنید در یک سازمان بزرگ با تیمهای علم داده و هوش تجاری کار میکنید که هر دو به دادههای شما وابستهاند. شما ممکن است دادههای ساختارنیافته را در یک دریاچه داده ذخیره کنید تا دانشمندان داده از آنها برای تحلیل اکتشافی استفاده کنند. همچنین ممکن است دادههای سازماندهیشده را در یک پایگاه داده رابطهای یا یک انبار داده اختصاصی ذخیره کنید تا تیم هوش تجاری در گزارشهای خود به کار ببرد.
تصویر زیر یک خط لوله داده که در آن دادهها از منابع مختلف وارد شده و سپس به بخشهای مختلف سازمان هدایت میشوند. برخی از بخشها مانند دریاچه داده، پایگاه داده رابطهای و انبار داده نیز در این تصویر نشان داده شدهاند:
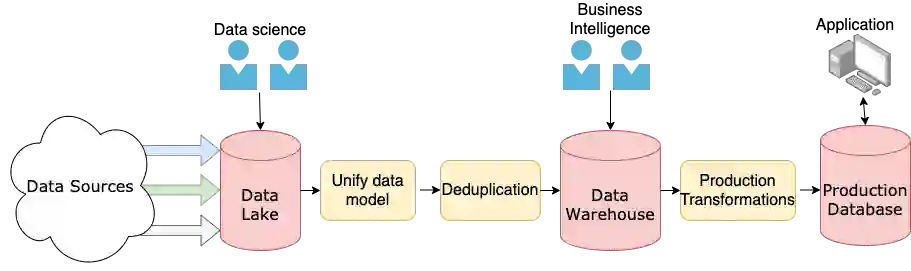
در این تصویر، یک خط لوله داده فرضی را مشاهده میکنید که بخشهای مختلف سازمان در مراحل مختلف آن به دادهها دسترسی پیدا میکنند. برخی از بخشها مانند دریاچه داده، پایگاه داده رابطهای و انبار داده نیز در این تصویر نشان داده شدهاند.
اینکه در کدام مرحله از خط لوله داده به دادهها دسترسی پیدا شود، بستگی به این دارد که مشتری نهایی شما چه کسی باشد.
اگر مشتری شما یک تیم محصول است، پس داشتن یک مدل داده با معماری خوب بسیار مهم است. یک مدل دادهی دقیق میتواند باعث شود که یک اپلیکیشن کند و غیرقابل پاسخگویی، به اپلیکیشنی تبدیل شود که به نظر میرسد از قبل میداند کاربر میخواهد به چه دادههایی دسترسی پیدا کند. این نوع تصمیمات اغلب نتیجه همکاری بین تیمهای محصول و مهندسی داده است.
پاکسازی داده
پاکسازی داده با نرمالسازی داده همراستا است. برخی حتی نرمالسازی داده را زیرمجموعهای از پاکسازی داده در نظر میگیرند. اما در حالی که نرمالسازی داده بیشتر بر روی مطابقت دادن دادههای ناهمگون با یک مدل داده خاص تمرکز دارد، پاکسازی داده شامل اقداماتی است که باعث یکنواختتر و کاملتر شدن دادهها میشود، از جمله:
- تبدیل دادههای یکسان به یک نوع واحد (برای مثال، تبدیل رشتههای موجود در یک فیلد عددی به عدد صحیح)
- اطمینان از اینکه تاریخها در یک فرمت باشند
- پر کردن فیلدهای خالی در صورت امکان
- محدود کردن مقادیر یک فیلد به یک محدوده مشخص
- حذف دادههای خراب یا غیرقابل استفاده
پاکسازی داده میتواند در مراحل رفع تکرار و یکسانسازی مدل داده در نمودار بالا جای گیرد. با این حال، در واقعیت، هر یک از این مراحل بسیار گسترده هستند و میتوانند شامل هر تعداد مرحله و فرآیند جداگانه باشند.
اقدامات خاصی که برای پاکسازی داده انجام میدهید، به شدت به ورودیها، مدل داده و نتایج مورد نظر بستگی دارد. با این حال، اهمیت دادههای پاکشده همواره ثابت است:
- دانشمندان داده به آن نیاز دارند تا تحلیلهای دقیقی انجام دهند.
- مهندسان یادگیری ماشین به آن نیاز دارند تا مدلهای دقیق و قابل تعمیم بسازند.
- تیمهای هوش تجاری به آن نیاز دارند تا گزارشها و پیشبینیهای دقیقی را برای کسب و کار ارائه دهند.
- تیمهای محصول به آن نیاز دارند تا اطمینان حاصل کنند که محصولشان دچار نقص نشده و اطلاعات نادرستی به کاربران ارائه ندهد.
مسئولیت پاکسازی داده بر عهده افراد مختلفی است و به سازمان کلی و اولویتهای آن بستگی دارد. به عنوان یک مهندس داده، شما باید تا حد امکان برای خودکار کردن پاکسازی تلاش کنید و به طور مرتب بر دادههای ورودی و ذخیرهشده نظارت داشته باشید.
دسترسی به داده
دسترسی به داده به اندازه نرمالسازی و پاکسازی داده مورد توجه قرار نمیگیرد، اما میتوان گفت که یکی از مهمترین مسئولیتهای یک تیم مهندسی داده با رویکرد مشتریمحور است.
دسترسی به داده به این معنی است که دسترسی و درک داده برای مشتریان چقدر آسان است. این مفهومی است که بسته به مشتری به شکلهای بسیار متفاوتی تعریف میشود:
- تیمهای علم داده ممکن است به سادگی به دادههایی نیاز داشته باشند که با نوعی زبان پرسوجو قابل دسترسی باشند.
- تیمهای تحلیل ممکن است دادههایی را ترجیح دهند که بر اساس برخی معیارها گروه بندی شده باشند و از طریق پرسوجوهای اولیه یا رابط گزارشدهی قابل دسترسی باشند.
- تیمهای محصول اغلب به دادههایی نیاز دارند که از طریق پرسوجوهای سریع و ساده که به دفعات تغییر نمیکند، قابل دسترسی باشند و بر عملکرد و قابلیت اطمینان محصول تمرکز داشته باشند.
از آنجایی که سازمانهای بزرگتر همین دادهها را برای این تیمها و سایرین فراهم میکنند، بسیاری از آنها به سمت توسعه پلتفرمهای داخلی خود برای تیمهای مختلفشان حرکت کردهاند. یک مثال عالی و بالغ از این، سرویس حمل و نقل Uber است که بسیاری از جزئیات پلتفرم دادههای بزرگ (Big Data) چشمگیر خود را به اشتراک گذاشته است.
در واقع، بسیاری از مهندسان داده خود را در حال تبدیل شدن به مهندسان پلتفرم میبینند و اهمیت مداوم مهارتهای مهندسی داده را برای کسبوکارهای دادهمحور آشکار میکنند. از آنجایی که دسترسی به داده به طور مستقیم با نحوه ذخیره داده مرتبط است، یکی از اجزای اصلی مرحله بارگذاری (Load) فرایند ETL است که به نحوه ذخیره داده برای استفاده بعدی اشاره دارد.
حالا که با برخی از مشتریان رایج مهندسی داده آشنا شدید و در مورد نیازهای آنها آموختید، وقت آن است که نگاه دقیقتری به مهارتهایی بیندازید که میتوانید برای برآوردن آن نیازها توسعه دهید.
فناوریهای پایگاه داده
در حوزه مهندسی داده، جابجایی مستمر دادهها ایجاب میکند که تسلط کافی بر پایگاههای داده داشته باشید. به طور کلی، فناوریهای پایگاه داده را میتوان به دو دسته اصلی تقسیم کرد: SQL و NoSQL.
پایگاههای داده SQL، سیستمهای مدیریت پایگاه داده رابطهای (RDBMS) هستند که ماهیتا رابطهای بوده و از طریق زبان پرسوجوی ساختیافته (SQL) مدیریت و بازیابی دادهها انجام میپذیرد. این نوع پایگاههای داده معمولا برای مدلسازی دادههایی با روابط مشخص، مانند دادههای سفارش مشتری، به کار میروند.
NoSQL که به معنای «غیر SQL» است، طیف وسیعی از پایگاههای داده را در بر میگیرد که معمولا برای ذخیرهسازی دادههای غیر رابطهای مورد استفاده قرار میگیرند. نمونههایی از این دست عبارتند از:
- ذخیرهسازهای کلید-مقدار مانند Redis یا DynamoDB سرویس ابری آمازون
- ذخیرهسازهای سند (document) مانند MongoDB یا Elasticsearch
- پایگاههای داده گراف مانند Neo4j
- سایر ذخیرهسازهای دادهای با شیوع کمتر
اگرچه اشراف کامل بر تمامی ظرایف فناوریهای پایگاه داده ضرورت ندارد، اما درک نقاط قوت و ضعف این سیستمهای مختلف و کسب مهارت یادگیری سریع یک یا دو مورد از آنها، امری ضروری است.
با توجه به مهاجرت روزافزون سیستمها به ابر، خطوط لوله داده (Data Pipeline) نیز معمولا به صورت توزیعشده در سراسر سرورها یا خوشههای متعدد، چه در ابر خصوصی و چه در محیطهای دیگر، مستقر میگردند. به همین دلیل، درک سیستمهای توزیعشده و مهندسی ابر برای یک مهندس داده آیندهنگر ضروری است.
سیستمهای توزیعشده و مهندسی ابر
یکی از مزایای اصلی تکنیکهای مهندسی داده مانند خطوط لوله ETL، قابلیت پیادهسازی آنها در سیستمهای توزیعشده است. الگوی رایجی در این زمینه، اجرای بخشهای مستقل یک خط لوله روی سرورهای جداگانه است که توسط یک صف پیام مانند RabbitMQ یا Apache Kafka هماهنگسازی میشوند.
درک نحوه طراحی این سیستمها، مزایا و معایب آنها و زمان مناسب برای استفاده از آنها، از اهمیت ویژهای برخوردار است. این سیستمها نیازمند سرورهای متعدد هستند و تیمهای پراکنده جغرافیایی نیز اغلب به دادههای موجود در آنها نیاز دارند. ارائهدهندگان ابر خصوصی مانند Amazon Web Services، Google Cloud و Microsoft Azure ابزارهای بسیار محبوبی برای ساخت و استقرار سیستمهای توزیعشده به شمار میروند.
داشتن درک اولیه از مهمترین خدمات ارائهدهندگان ابر و همچنین برخی از ابزارهای پیامرسانی توزیعشده محبوب، به شما در یافتن اولین شغل مهندسی داده کمک شایانی خواهد کرد. انتظار میرود که در حین کار، تسلط بر این ابزارها را به طور عمیقتری فرا بگیرید.
تفاوت در رویکرد: دانشمندان داده در مقابل مهندسان داده
متخصصان علم داده اغلب دارای پیشینه تحصیلی در علوم پایه یا آمار هستند و سبک کاری آنها نیز این موضوع را منعکس میکند. آنها بر روی پروژههایی متمرکز هستند که به یک سؤال خاص پژوهشی پاسخ میدهند. در مقابل، تیم مهندسی داده بر ساخت محصولات داخلی قابل توسعه، قابل استفاده مجدد و با کارایی بالا تمرکز دارد.
یک مثال برجسته از فعالیت دانشمندان داده در پاسخ به پرسشهای پژوهشی را میتوان در شرکتهای فعال در حوزه زیست فناوری و فناوری سلامت مشاهده نمود. در این شرکتها، دانشمندان داده به کاوش در دادههای مربوط به تداخلات دارویی، عوارض جانبی، نتایج بیماریها و موارد بسیار دیگری میپردازند.
هوش تجاری
هوش تجاری (BI) شباهتهایی به علم داده دارد، اما چند تفاوت مهم نیز وجود دارد. در حالی که علم داده بر پیشبینی و ساختن مدلهایی برای آینده تمرکز دارد، هوش تجاری بر ارائه نمای کلی از وضعیت فعلی کسب و کار متمرکز است.
هر دوی این گروهها از خروجی تیمهای مهندسی داده استفاده میکنند و حتی ممکن است از یک مجموعه داده مشترک استفاده کنند. با این حال، هوش تجاری بر تحلیل عملکرد کسب و کار و تهیه گزارش از دادهها متمرکز است. سپس این گزارشها به مدیران برای تصمیمگیری در سطح کلان کسب و کار کمک میکند.
مانند دانشمندان داده، تیمهای هوش تجاری نیز برای ساخت ابزارهایی که به آنها امکان تحلیل و گزارشدهی از دادههای مرتبط با حوزه کاریشان را میدهد، به مهندسان داده وابسته هستند.
مهندسی یادگیری ماشین
مهندسان یادگیری ماشین گروه دیگری هستند که اغلب با آنها در ارتباط خواهید بود. ممکن است کارهای مشابهی با آنها انجام دهید، یا حتی در یک تیم با مهندسان یادگیری ماشین قرار بگیرید.
مانند مهندسان داده، مهندسان یادگیری ماشین نیز بیشتر بر ساخت نرمافزارهای قابلاستفاده مجدد تمرکز دارند و بسیاری از آنها دارای پیشینه علوم کامپیوتر هستند. با این حال، تمرکز آنها کمتر روی ساختن برنامههای کاربردی و بیشتر روی ساخت مدلهای یادگیری ماشین یا طراحی الگوریتمهای جدید برای استفاده در مدلها است.
مدلهایی که مهندسان یادگیری ماشین میسازند، اغلب توسط تیمهای محصول در محصولات رو به مشتری استفاده میشوند. دادههایی که شما به عنوان یک مهندس داده تأمین میکنید، برای آموزش مدلهای آنها استفاده میشود و این امر، کار شما را به عنوان زیربنای اساسی برای توانمندیهای هر تیم یادگیری ماشینی که با آن کار میکنید، تبدیل میکند.
به عنوان مثال، یک مهندس یادگیری ماشین ممکن است یک الگوریتم توصیهای جدید برای محصول شرکت شما توسعه دهد، در حالی که یک مهندس داده دادههایی را برای آموزش و آزمایش آن الگوریتم در اختیار او قرار میدهد.
درک یک نکته مهم است: زمینههایی که در اینجا به آنها نگاه کردهاید، اغلب کاملاً تفکیکشده نیستند. افراد با پیشینه علم داده، هوش تجاری یا یادگیری ماشین ممکن است در یک سازمان کار مهندسی داده انجام دهند، و شما به عنوان یک مهندس داده، ممکن است برای کمک به این تیمها در کارشان فراخوانده شوید.
ممکن است یک روز خود را در حال بازطراحی یک مدل داده، روز دیگر در حال ساخت یک ابزار برچسبگذاری داده و بعد از آن در حال بهینهسازی یک چارچوب یادگیری عمیق داخلی ببینید. مهندسان داده خوب انعطافپذیر، کنجکاو و مشتاق امتحان کردن چیزهای جدید هستند.
منبع
What Is Data Engineering and Is It Right for You?
اگر بدنبال یک دورهی کامل و جامع از مهندسی داده هستید، این را ببینید

