


مقدمه
مدیریت دادههای گمشده یا مقادیر از دست رفته گام مهمی در پاکسازی دادهها (Data cleaning) و پیش پردازش دادهها (Preprocessing) در بحث یادگیری ماشین (Machin Learning) یا دادهکاوی (Data Mining) است که می تواند بر اعتبار و قابلیت اطمینان مدل تأثیر بگذارد. دلیل اهمیت گمشدگی دادهها این است که تقریباً تمام تکنیکهای آماری کلاسیک و مدرن عملکرد آنها براساس دادههای کامل است (یا به آنها نیاز دارند). دلیل دیگر اینکه اغلب بستههای آماری رایج در بسیاری از نرمافزارهای آماری حداقل گزینههای مطلوب آنها برای مقابله با دادههای از دست رفته حذف دادههای گمشده از تجزیه و تحلیل است. در این آموزش موارد زیر پوشش داده خواهد شد:
- مکانیزمهای گمشدگی دادهها
- چگونگی برخورد با دادههای گمشده
دادهی گمشده چیست؟
علــی رغــم ایــن کــه در اکثــر تحقیقات علمی روشهای استنباط براساس دادههای کامل میباشد، ولی در بسیاری از موارد به ویژه وقتی با دادههای حجیم سروکار داریم، جمـع آوری دادههـا به طور کامـل امکـان پـذیر نمیباشـد. بنابراین اگر دادهای یا مقداری از هر متغیری از هر شرکتکننده وجود نداشته باشد، محقق با دادههای گمشده یا ناقص سروکار دارد.
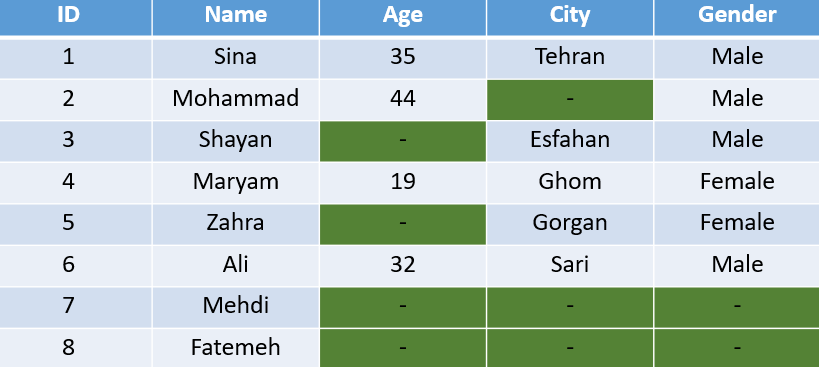
برخی از دلایل گمشدگی دادهها
- برخـــی از افـــراد شـــرکت کننده در مطالعـه از ادامـــه همکـــاری انصـــراف میدهند.
- برخـــی از افـــراد شـــرکت کننده از پاسـخ دادن بـه برخـی از سـئوالات اجتنـاب میکنند.
- محققـین، تکنسـینها، جمـع آوریکننـده دادههــا ممکن است اشتباهاتی را انجام دهند.
- در بعضی از مطالعات نظر سنجی، افـرادی قـادر به اظهار نظـر دقیـق نباشـند.
- در یـک مطالعه گذشته نگر به علت نقص مدارک و سـوابق ممکـن است برخی از اطلاعات در دسترس نباشد.
- ممکن است بـه علـت نقـص یـا ضـعف دسـتگاه و تجهیـزات، امکـان مشـاهده و انـدازه گیـری وجـود نداشـته باشد.
تاثیرات گمشدگی دادهها
- اکثر کتابخانههای R و Python مورد استفاده در یادگیری ماشین و دادهکاوی معمولا ابزاری برای مدیریت خودکار دادههای گمشده ندارند و می توانند منجر به خطا شوند.
- دادههای گمشده میتواند باعث ایجاد اغتشاش در توزیع متغیر شود، یعنی میتوانند باعث بیشبرازش یا کمبرازش مدلها شوند.
- دادههای گمشده میتوانند باعث یک سوگیری (اریبی) در مجموعه داده شوند و بنابراین تجزیه و تحلیل آمـاری را بـه سـوی نتـایج اریب سوق داده و نهایتاً دستیابی به یک نتیجهگیری مفیـد از دادههای جمع آوری شده را با مشـکل مواجـه میسـازد و میتوانند منجر به تجزیه و تحلیل نادرست مدل شوند.
مکانیزمهای گمشدگی
- هنگام کاوش در دادههای گمشده یا از دست رفته، مهمترین چیز یافتن و پی بردن به مکانیزم گمشدگی است یعنی اینکه دادههای گمشده به چه دلیل گمشدهاند؟
- یعنی گمشدگی دادهها هم میتواند به صورت تصادفی باشد یا اینکه به دلیل غیرتصادفی و هدفمند عدم پاسخ صورت گرفته باشد. به عنوان مثال، اکثر زنان در یک مطالعه از پاسخ دادن به سوالاتی که مربوط به سن باشند ممکن است به آن سوالات پاسخ ندهند یا معمولا مردان ممکن است از پاسخگویی به سوالات در مورد درآمد خودداری کنند. بنابراین شناخت سازوکار گمشدگی بسیار مهم میباشند.
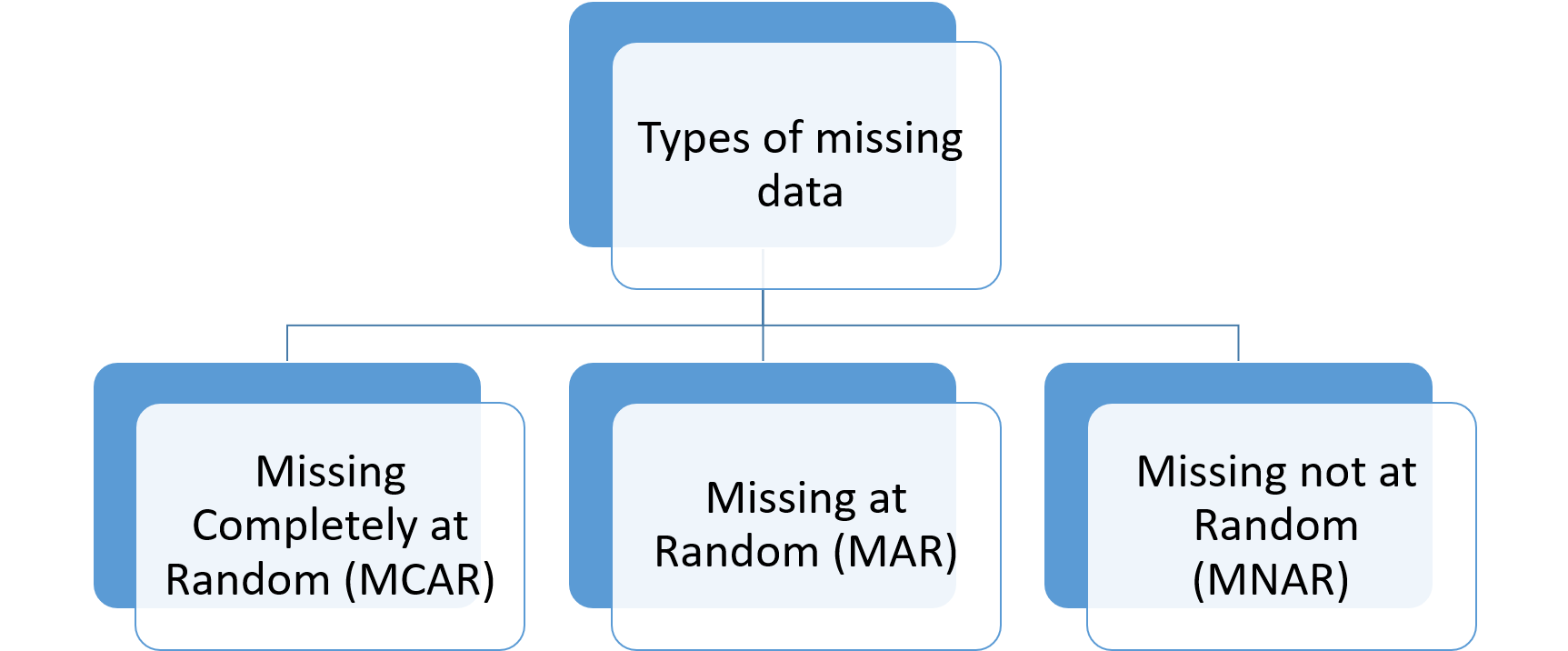
روبین در سال 1976 انواع داده های گمشده را بر اساس دلایل گمشدگی دادهها به سه دسته زیر تقسیمبندی کرد:
ادامه مطالب بسیار ارزشمند و بینظیر این مقاله را به صورت PDF در فایل زیر مطالعه نمائید. در ادامه کار به نحوهی کار با دادههای گمشده خواهیم پرداخت همچنین میتوانید ویدیوی ضبط شده توسط آقای دکتر عبدالسعید توماج را نیز که در کانال یوتیوب علم داده به انتشار رسیده، مشاهده نمائید.
- دانلود مابقی مقاله بصورت PDF
- مشاهده قسمت اول ویدیو (مربوط به این مقاله)
- مشاهده قسمت دوم ویدیو (مربوط به این مقاله)